1. Установите SQL 2012 на все серверы, которые вы планируете задействовать в Always On. Убедитесь, что конфигурация папок и дисков на этих серверах идентична, как и настройки SQL Server. Используйте доменный аккаунт для запуска SQL Server service и SQL Agent service (в противном случае придется отдельно конфигурировать аккаунты для Always on endpoints.
2. Установите .NET Framework 3.5.1 и Failover Cluster features на те же серверы:

3. После установки, запустите создание кластера:

3.1. Добавьте серверы, участвующие в реплике:

3.2. Вам необязательно делать проверку конфигурации кластера:

3.3. Выбираете DNS-name и IP-address для управления кластером (это не будет адрес SQL сервера):

3.4. Кластер создан и готов к работе:

3.5. Необходимо сконфигурировать кворум для данного кластера. Раз мы не использует shared storage, логичным вариантом будет использовать Node and File Share majority. Тыкаем правой мышкой в имя кластера - More Actions - Configure Cluster Quorum Settings:

выбираем соответствующую настройку

и выбираем File share на некоем третьем файлсервере, которая должна быть доступна бОльшую часть времени. Как видно из описания данного варианта кворума, кластер будет корректно обрабатывать отказы в случае, если
- все узлы, кроме одного вышли из строя и доступна сетевая папка или
- если доступны не менее двух узлов и сетевая папка недоступна.
4. Теперь вы можете включить Always On feature в SQL Configuration manager:

5. Все готово для конфигурирования Always On. Кликаем правой мышкой на Availability Groups - New Availability Group:

5.1. Конфигурируем следующие параметры:

- имя группы
- Availability mode. Synchronous для синхронной репликации (когда транзакция закрывается только после репликации) и Asynchronous (которая работает быстрее, но в случае сбоя возможна потеря данных на реплике). Если вы планируете использовать автоматическое восстановление (failover) после сбоя, выбирайте Synchronous;
- Failover mode (Automatic/Manual): Восстановление после сбоя (автоматическое/ручное);
- Readable secondary. Будет ли вторичная реплика на этом сервере доступна для чтения. Варианты No - не будет, Read-intent only - будет, если в application's connection string использован хинт ApplicationIntent=ReadOnly, Yes - будет, даже без хинта (используется для старых приложений, не поддерживающих ApplicationIntent).
5.2. Добавляем базы данных в Availability Group. В случае сбоя эти базы данных перейдут на другую доступную реплику. Тыкаем правой мышкой на Availability Databases - Add database:

5.3. отмечаем базы данных

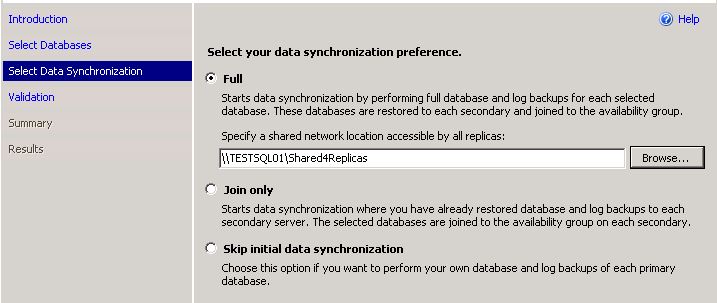
5.4. выбираем, как будем выполнять исходную синхронизацию. Full - если мы желаем, чтобы SQL Server сделал это за нас, мы должны создать на Primary реплике общую сетевую папку, доступную для всех остальных серверов (туда будет выполнен начальный backup баз данных). Join Only - если мы уже скопировали базы данных вручную на все сервера и оставили их в Restoring mode. Skip - если мы все это сделаем позже.
После всех проверок и завершения процесса мы увидим наши базы данных в списке Availability Databases:

5.5. Теперь мы добавляем остальные серверы в ту же Availability Group. Для этого тыкаем правой мышкой в Availability Replicas - Add replica:

Добавляем серверы и выставляем аналогичные вышеописанным параметры:

После добавления вы видите замечательную картинку с вашими базами данных:

5.6. Теперь добавляем Availability Group Listener. Это DNS-имя, IP-address и порт этой Availability group в сети (с точки зрения приложений это будет выглядеть как SQL server, на котором расположены только эти базы данных). Тыкаем правой мышкой на Availability Group Listeners - Add listener:

Конфигурируем имя, IP и порт:

И после этого можем подключиться к нашему бесперебойному решению, используя вышесконфигурированный бесперебойный адрес и имя:

Вы также увидите вашу Availability Group, как сервис в консоли управления кластером:

Ваш высокоустойчивый к отказам кластер готов. Можете попробовать потестировать его, добавить дополнительные реплики, сконфигурировать приоритет бэкапов (по умолчанию бэкапы будут преимущественно выполняться с вторичной реплики) и т.д.

2 комментария:
А как правильно создать кластер в Windows 2012R2 ??
Коллега, доброго дня, а вот вы пишите: "(с точки зрения приложений это будет выглядеть как SQL server, на котором расположены только эти базы данных)"
у меня предположим 2 сервера srv1 & srv2 на них расположены отдельные 5 БД, я создал группу, создал листинг, закинул в группу предположим 2 базы, подключаюсь на этот листинг и вижу снова все те же 5 БД (те что находятся на primary сервере).
Отсюда вопрос - нормальное ли это поведение?
Отправить комментарий